一、Scrapy框架简介与核心流程图
Scrapy是一个基于Python开发的高效、快速的网络爬虫框架,广泛应用于数据抓取、信息提取和结构化数据存储。其设计遵循模块化原则,使得开发者能够灵活定制爬虫流程。
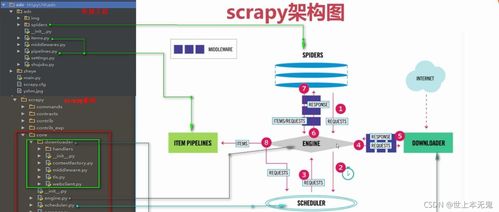
Scrapy核心架构流程图解析
Scrapy的工作流程可以概括为以下几个关键步骤,形成一个清晰的闭环系统:
- 引擎(Engine):作为整个框架的控制中心,负责调度所有组件之间的数据流。
- 调度器(Scheduler):接收引擎发来的请求(Request),并将其排队,等待引擎需要时再交还。
- 下载器(Downloader):根据引擎的指令,从互联网上下载网页内容,并将响应(Response)返回给引擎。
- 爬虫(Spider):这是用户编写的核心逻辑部分。它负责解析下载器返回的响应,提取结构化数据(Item)和新的后续请求(Request)。
- 项目管道(Item Pipeline):处理爬虫提取到的Item。常见的操作包括数据清洗、验证、去重以及存储到数据库或文件中。
- 下载器中间件(Downloader Middlewares) 和 爬虫中间件(Spider Middlewares):这两个是钩子框架,允许用户自定义代码,以全局方式处理请求和响应,例如添加代理、更换User-Agent等。
流程简述:引擎从爬虫获取初始请求,交给调度器排队。引擎再从调度器获取请求,通过下载器中间件发送给下载器。下载器获取网页响应后,通过引擎和爬虫中间件传递给爬虫。爬虫解析响应,产生新的Items和Requests,Items交给管道处理,新的Requests则返回给引擎,开启下一轮循环。
二、Scrapy的智能化安装工程
传统的安装方式可能涉及手动解决依赖和版本冲突。如今,我们可以利用现代Python包管理工具实现更智能、更便捷的安装。
环境准备
确保系统已安装Python(建议3.6及以上版本)和pip包管理工具。
推荐安装方法
1. 使用pip进行基础安装(最常用)
打开终端(Windows为CMD或PowerShell,Mac/Linux为Terminal),执行以下命令:
`bash
pip install scrapy
`
这是最直接的方式。pip会自动从Python官方包索引(PyPI)下载Scrapy及其所有核心依赖(如Twisted, lxml, pyOpenSSL等)。
2. 创建虚拟环境(最佳实践)
为避免项目间的包版本冲突,强烈建议在虚拟环境中安装。
`bash
# 安装虚拟环境管理工具(如果未安装)
pip install virtualenv
# 为你的爬虫项目创建一个新的虚拟环境
virtualenv scrapy_env
# 激活虚拟环境
Windows:
scrapy_env\Scripts\activate
# Mac/Linux:
source scrapy_env/bin/activate
# 在激活的虚拟环境中安装Scrapy
pip install scrapy
`
3. 使用conda进行科学计算环境集成安装
如果你使用Anaconda或Miniconda进行Python数据科学开发,conda能更好地管理二进制依赖。
`bash
conda install -c conda-forge scrapy
`
-c conda-forge指定从conda-forge社区频道安装,通常版本更新更快。
4. 验证安装
安装完成后,在命令行中输入以下命令验证是否成功:
`bash
scrapy version
`
如果成功,将显示已安装的Scrapy版本号(例如 Scrapy 2.11.0)。
智能化安装与问题解决
- 自动依赖解析:现代pip版本具备强大的依赖解析能力,能自动处理大部分兼容性问题。
- 使用pip install --upgrade pip:确保pip本身是最新版本,以获得最佳的安装体验和问题修复。
- 针对特定操作系统的预编译包:在Windows上,如果安装Twisted(Scrapy的核心依赖之一)失败,可以访问Unofficial Windows Binaries for Python Extension Packages网站,手动下载对应Python版本的Twisted的.whl文件,然后通过pip install 下载的文件名.whl进行安装,再重新安装Scrapy。
- 镜像加速:在国内,可以使用清华大学、阿里云等PyPI镜像源来大幅提升下载速度。
`bash
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
`
通过理解Scrapy的清晰架构流程,并采用上述智能化的安装方法,你可以快速、无痛地搭建起强大的爬虫开发环境,从而更专注于爬虫业务逻辑的实现。